
1. Introduction
There are many ways to design systems for data-intensive workloads. This article presents one practical approach: a scalable execution architecture built on a clear separation of orchestration, scheduling, execution, and state management.
The architecture is composed of loosely coupled layers, each responsible for a distinct concern. Orchestration defines when work should happen and the order in which it should be executed, scheduling determines how work is assigned to available resources, execution performs the work itself, and state is managed externally through shared storage. These layers interact through well-defined boundaries, allowing each component to scale and evolve independently without introducing tight coupling. By keeping these concerns separate, the system remains predictable under load and easier to operate in distributed environments.
This architecture has proven effective for workloads that are heterogeneous, resource-intensive, and executed across shared compute infrastructure. While the specific tools used here include Airflow, SLURM, and containerized applications, the underlying design principles are broadly applicable to a wide range of systems that require scalable and reliable execution
2. System Architecture
The system is organized into four logical layers: hardware, data, worker, and orchestration. Each layer encapsulates a specific responsibility, allowing the system to scale independently across compute, storage, and execution domains. This separation also ensures that changes in one layer do not introduce unintended coupling in others.
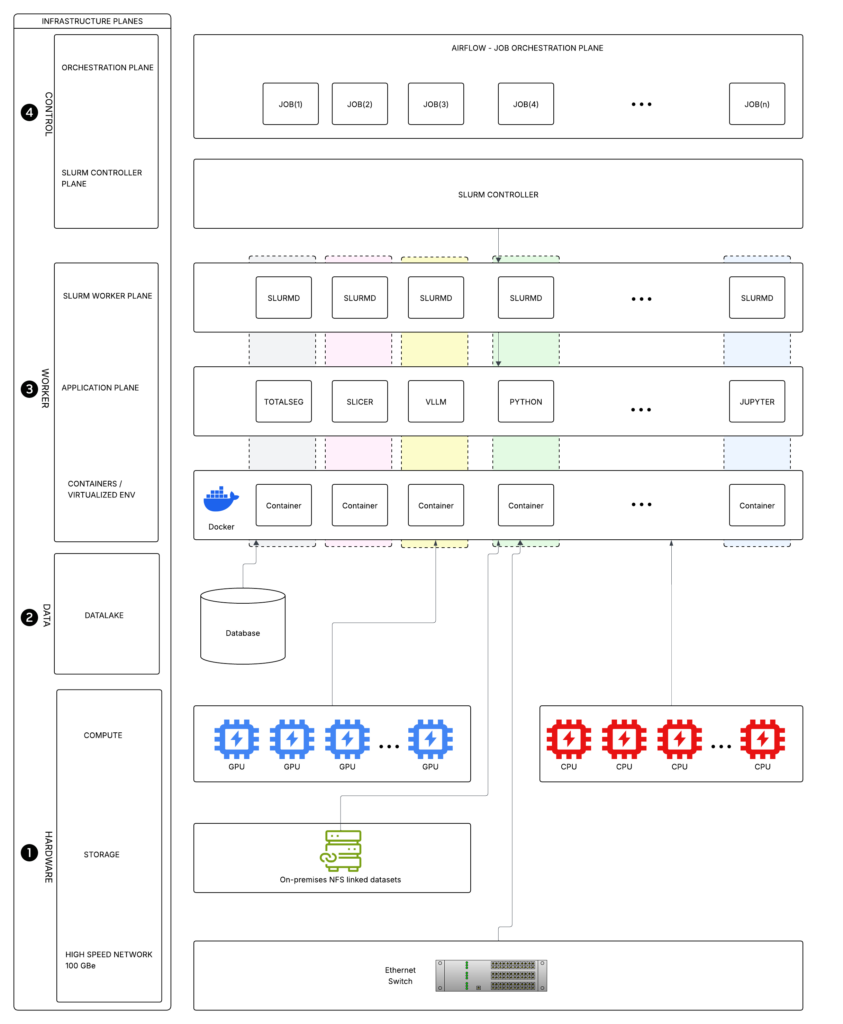
Figure 1 – System architecture for a distributed execution pipeline
The hardware layer provides the underlying compute and storage infrastructure required to support distributed execution. It consists of GPU-enabled nodes for compute-intensive workloads, CPU nodes for general-purpose processing, high-speed network connectivity across nodes, and shared storage accessible from all compute resources. Rather than treating these machines individually, the system views them as a unified pool of resources. All higher-level components interact with this layer through abstractions provided by the scheduling and execution systems.
The data layer serves a dual role as both persistent storage and the primary medium for coordination between stages of execution. All inputs, intermediate artifacts, and outputs are stored in a shared filesystem and organized into structured directories that reflect their progression through the system. Execution state is implicitly encoded in this structure. Directories represent units of work, stage-specific locations indicate progression, and lightweight marker files signal ownership, completion, or retry conditions. This approach allows stages to operate independently without requiring direct communication or centralized coordination.
The worker layer is responsible for executing all processing tasks and is composed of containerized workloads running across distributed compute nodes. Each unit of work is executed as an isolated job, with dependencies fully encapsulated within the container. Workers retrieve input data from shared storage, perform processing, and write results back to well-defined locations. Because execution is isolated and stateless with respect to the system, workloads can run on any compatible node, making execution both repeatable and portable.
The orchestration layer coordinates execution while remaining decoupled from the actual work being performed. A workflow engine defines stage boundaries and triggers execution, while a dedicated scheduler is responsible for allocating resources and placing workloads on appropriate nodes. This separation ensures that orchestration logic remains lightweight, while resource-intensive decisions are delegated to a system designed specifically for distributed scheduling.
Execution progresses through a series of independent stages. Each stage identifies available work from the data layer, claims ownership using lightweight coordination mechanisms, processes the data in isolation, and writes results to the next stage. There is no global execution state maintained across the system. Instead, progression is driven by the presence of data and stage-specific markers. This allows multiple datasets to be processed concurrently, with each stage operating independently across the cluster.
3. Key Design Decisions
The architecture is shaped by a small number of practical design decisions that prioritize operational simplicity, scalability, and failure isolation. These decisions are not theoretical—they are reflected directly in how the system behaves under real workloads.
A foundational decision is the strict separation between orchestration and execution. The workflow engine defines stage boundaries and triggers work, but does not execute it. Execution is delegated entirely to a dedicated scheduler. In this implementation, Airflow is used to define workflows and initiate jobs, while SLURM handles queueing, resource allocation, and execution across the cluster. This separation avoids a common failure mode where orchestration systems become overloaded with execution responsibilities, and allows each component to operate within its intended role.
Another key decision is to use the shared filesystem as the primary coordination layer. Instead of relying on a centralized database or message queue, the system discovers and progresses work based on directory structure and lightweight markers. A stage identifies work by locating directories that meet specific criteria, claims ownership by creating a marker file such as taken.phase4, and signals completion by writing outputs to a downstream location. This approach makes system state directly visible and simplifies debugging, since the entire system can be understood by inspecting the filesystem. It also avoids the need for global coordination when handling partial failures.
Execution is structured as a sequence of independent stages, each responsible for a specific transformation. These stages do not communicate directly. Instead, each stage reads from a well-defined input location, processes data independently, and writes results to a downstream location. In practice, this often takes the form of a progression such as PHASE_2A → PHASE_2B → PHASE_3 → PHASE_4 → PHASE_5. Each phase represents a distinct unit of work and can be executed independently across multiple datasets, enabling parallel processing and clear boundaries for failure handling.
Each unit of work is designed to be both idempotent and isolated. Jobs operate only on their assigned dataset, and intermediate results are written to stage-specific directories. If a job fails, it can be retried without affecting other datasets, and partially completed work can be safely reprocessed. This is critical in distributed environments where failures are expected rather than exceptional.
All workloads are executed within containers, ensuring consistent runtime environments and isolating dependencies from the underlying system. In this implementation, containerized jobs are dispatched through SLURM, allowing the same workload to run on any compatible node without modification. This guarantees reproducibility and reduces operational friction when scaling across nodes.
The system also takes advantage of resource-aware scheduling. Workloads often have different requirements, particularly between CPU-bound and GPU-bound tasks. By using SLURM, jobs can explicitly request resources such as GPUs, memory, and CPUs. This allows compute-intensive stages to run on GPU nodes while lighter preprocessing tasks execute on CPU nodes, enabling efficient utilization of cluster resources.
Finally, failure handling is localized and predictable. Failures are managed at the level of individual datasets and stages. Jobs can be requeued, retry markers can track repeated attempts, and incomplete outputs do not block the entire system. Because stages are independent and idempotent, failures do not cascade across the system, and recovery can be performed without global coordination.
4. Execution Model
Execution in the system is fully asynchronous and stage-driven. Each stage operates independently, continuously polling its input location for available work. There are no explicit dependencies enforced between stages at runtime, and no component waits for another stage to complete before proceeding. As soon as data becomes available in a stage’s input location, it is eligible for processing.
Work is initiated through the orchestration layer, which triggers jobs corresponding to different stages. These jobs are scheduled onto available compute resources and executed as independent workers. Once running, each worker is responsible for discovering work, claiming it, processing it in isolation, and writing results back to shared storage.
Coordination between stages is achieved entirely through the data layer. Each stage reads from a well-defined input location and writes its output to a downstream location. This movement of data implicitly drives progression through the system. Because stages do not communicate directly and do not rely on centralized state, the system remains simple and predictable even as it scales.
This execution model allows multiple datasets to move through different stages simultaneously. At any given time, different stages may be operating on different datasets without coordination or blocking. The result is a system that is naturally parallel, resilient to partial failures, and straightforward to operate.
flowchart LR
subgraph Orchestration
A[Workflow Trigger]
end
subgraph Scheduler
B[Scheduler]
end
subgraph Workers
W1[Stage 1 Worker]
W2[Stage 2 Worker]
W3[Stage 3 Worker]
W4[Stage 4 Worker]
W5[Stage N Worker]
end
subgraph DataLayer
S1[(Stage 1 Input)]
S2[(Stage 2 Input)]
S3[(Stage 3 Input)]
S4[(Stage 4 Input)]
SN[(Stage N Input)]
end
%% Orchestration → Scheduler
A --> B
%% Scheduler → Workers
B --> W1
B --> W2
B --> W3
B --> W4
B --> W5
%% Polling behavior (asynchronous)
W1 -->|Poll| S1
W2 -->|Poll| S2
W3 -->|Poll| S3
W4 -->|Poll| S4
W5 -->|Poll| SN
%% Marker / ownership
W1 -->|Create Marker| S1
W2 -->|Create Marker| S2
W3 -->|Create Marker| S3
W4 -->|Create Marker| S4
%% Consume & Process
W1 -->|Consume & Process| S1
W2 -->|Consume & Process| S2
W3 -->|Consume & Process| S3
W4 -->|Consume & Process| S4
%% Data progression
W1 -->|Write Output| S2
W2 -->|Write Output| S3
W3 -->|Write Output| S4
W4 -->|Write Output| SN
%% ===== Styling =====
classDef stage1 fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px;
classDef stage2 fill:#e8f5e9,stroke:#43a047,stroke-width:2px;
classDef stage3 fill:#fff3e0,stroke:#fb8c00,stroke-width:2px;
classDef stage4 fill:#fce4ec,stroke:#d81b60,stroke-width:2px;
classDef stageN fill:#ede7f6,stroke:#5e35b1,stroke-width:2px;
classDef infra fill:#f5f5f5,stroke:#616161,stroke-width:2px;
class W1,S1 stage1;
class W2,S2 stage2;
class W3,S3 stage3;
class W4,S4 stage4;
class W5,SN stageN;
class A,B infra;Figure 2 – Asynchronous execution model
4.1 Detailed Execution Flow
Execution begins when a dataset becomes available in the input location for the first stage. At this point, there is no explicit trigger tied to that specific dataset. Instead, stage workers are already running as part of the system and continuously polling their respective input locations for available work.
When a Stage 1 worker detects a new dataset, it attempts to claim ownership by creating a marker associated with that unit of work. This marker ensures that the dataset is not picked up concurrently by another worker. Once ownership is established, the worker proceeds to consume the dataset and execute the required processing in isolation. The processing itself runs within a containerized environment scheduled through the execution layer, ensuring consistency across nodes.
Upon successful completion, the worker writes the output to the input location of the next stage. This write operation is the only mechanism required to signal progression. There is no direct communication with downstream stages and no explicit notification or event emitted. The presence of new data in the downstream location is sufficient to make it eligible for processing.
Stage 2 operates in the same manner. Its workers continuously poll their input location and, upon detecting the newly written dataset, repeat the same sequence of actions: claim ownership, process the data, and write results to the next stage. This pattern continues across all stages in the system. Each stage is unaware of upstream or downstream execution state and operates solely based on the availability of data in its own input location.
Because each stage operates independently, multiple datasets can be in different stages of execution at the same time. While one dataset may be in Stage 3, another may still be in Stage 1, and yet another may be completing processing in a later stage. This results in natural parallelism across both datasets and stages without requiring explicit coordination or scheduling logic at the application level.
Failures are handled locally within each stage. If a worker fails during processing, the absence of a completion signal allows the dataset to be retried. Depending on the implementation, this may occur through scheduler-level requeueing or through subsequent polling cycles that detect incomplete work. Since processing is designed to be idempotent and scoped to individual datasets, retries do not require global coordination and do not impact other datasets in the system.
This execution model keeps the system simple. There are no global locks, no centralized state machines, and no dependency tracking between stages at runtime. Progression is entirely driven by data movement, and each stage performs a consistent, repeatable sequence of actions. This makes the system easier to reason about, easier to debug, and more resilient under real-world operating conditions.
5. Scaling and Resource Utilization
The architecture scales naturally because execution is decentralized and driven by independent workers. There is no central component responsible for coordinating execution across datasets or stages, which eliminates common bottlenecks seen in tightly coupled systems. As additional compute resources are introduced, overall system throughput increases proportionally without requiring changes to application logic.
Parallelism exists at multiple levels. At the dataset level, multiple datasets can be processed simultaneously, each progressing through the system independently. At the stage level, multiple workers can operate on different datasets within the same stage. Because stages do not block on one another, the system maintains a continuous flow of work across all stages, ensuring that available compute resources are consistently utilized.
Workloads often have different computational characteristics, particularly in environments that mix preprocessing, transformation, and compute-intensive tasks. By using a dedicated scheduler, workloads can request specific resources such as CPUs, GPUs, and memory. This allows compute-intensive stages to be placed on appropriate nodes while lighter workloads execute elsewhere. As a result, heterogeneous workloads can coexist efficiently within the same cluster without manual intervention.
The scheduler plays a critical role in maintaining this efficiency. It is responsible for queueing, resource allocation, and workload placement, ensuring that jobs are distributed across available resources in a balanced manner. Because scheduling is handled externally, the application layer remains simple and does not need to implement its own resource management logic.
In practice, this model results in high resource utilization and predictable scaling behavior. Adding capacity increases throughput, and the system continues to operate without requiring reconfiguration or rebalancing. This makes it well-suited for environments where workload characteristics and data volumes evolve over time.
6. Operational Considerations and Tradeoffs
While the architecture emphasizes simplicity, it is not without tradeoffs. These tradeoffs are deliberate and reflect practical decisions made to optimize for operability and reliability in real-world environments.
Using the filesystem as the coordination layer simplifies system design and improves observability, but it also places constraints on how state is represented. There is no centralized index of system state, and querying system-wide status requires inspecting the filesystem. For many workloads, this is acceptable and even desirable, but it may not be suitable for systems that require complex querying or transactional guarantees.
The absence of direct communication between stages reduces coupling but shifts responsibility to careful data organization. Each stage must adhere strictly to input and output conventions, as there is no runtime enforcement of contracts between stages. This requires discipline in how data is structured and validated.
Failure handling is straightforward but requires thoughtful design of idempotent processing. Since retries are driven by the absence of completion signals rather than explicit rollback mechanisms, each stage must be able to safely reprocess data without unintended side effects. This is a critical requirement and influences how intermediate artifacts are written and managed.
The reliance on polling introduces a tradeoff between responsiveness and resource utilization. Frequent polling reduces latency but increases overhead, while less frequent polling reduces overhead at the cost of delayed execution. In practice, this tradeoff is manageable and can be tuned based on workload characteristics.
Finally, while the architecture avoids the complexity of message queues and centralized state systems, it also forgoes some of their capabilities. Systems that require fine-grained event handling, strict ordering guarantees, or complex dependency management may benefit from alternative approaches. This architecture is best suited for workloads where independence, scalability, and operational simplicity are the primary concerns.
7. Reusability of the Pattern
Although the implementation described here is grounded in a specific use case, the underlying architecture is broadly applicable. The pattern of asynchronous, stage-driven execution combined with filesystem-based coordination can be adapted to a wide range of data-intensive systems.
Any workload that can be decomposed into independent stages with well-defined inputs and outputs can benefit from this approach. Examples include machine learning pipelines, large-scale data transformation systems, web crawling platforms, and batch-oriented analytics workflows. In each of these cases, the same principles apply: independent workers, shared storage, and data-driven progression.
The key requirement is that processing can be structured as a series of transformations where each stage operates on a self-contained unit of work. When this condition is met, the system can achieve high levels of parallelism without introducing complex coordination mechanisms.
This pattern is particularly effective in environments where infrastructure is shared across teams or workloads. By relying on standard components such as a scheduler and containerized execution, the system integrates naturally into existing compute environments without requiring specialized infrastructure.
8. Conclusion
Designing systems for data-intensive workloads often leads to increasing complexity as scale grows. Coordination, state management, and failure handling tend to become tightly coupled, making systems harder to reason about and operate.
The architecture presented here takes a different approach by emphasizing separation of concerns, independent execution, and data-driven progression. By combining a workflow engine for orchestration, a scheduler for execution, containerized workloads for isolation, and shared storage for coordination, the system achieves scalability without introducing unnecessary complexity.
The result is a system that is straightforward to understand, resilient under failure, and adaptable to a wide range of workloads. Rather than relying on tightly integrated components or complex coordination mechanisms, it leverages simple, well-defined interactions between layers.
This is not the only way to design such systems, but it is a practical approach that has proven effective in real-world environments. For workloads that can be expressed as independent stages operating on shared data, it provides a scalable and maintainable foundation for building reliable execution systems.